Multiagent Orchestration Needs a Testing Layer
Anthropic just shipped multiagent orchestration for Claude — agents that delegate tasks to specialized subagents and self-correct based on outcomes. Harvey, Netflix, and Wisedocs are already using it. The part nobody's talking about: when three agents collaborate on a result, who verifies the result actually works?
Key Takeaways
Multiagent systems fail differently than single agents. A subagent can complete its task correctly in isolation and still produce a broken end result because it misunderstood what the orchestrator needed.
Self-improving doesn't mean self-verifying. Claude's "dreaming" feature analyzes past sessions to improve future ones — but improvement and correctness are different goals. An agent can get better at producing wrong output faster.
ProgramBench proved that writing code is not the bottleneck. Meta's new benchmark gave AI agents compiled binaries and asked them to rebuild the source. Zero models fully solved any task — not because they couldn't write code, but because 248,000 behavioral tests caught every deviation.
Testing infrastructure is the missing layer in every agent architecture diagram. Agents need something outside themselves that continuously checks whether the thing they built actually works in production.
What Anthropic Actually Shipped
Claude Managed Agents launched three capabilities last week that matter here: dreaming, outcomes, and multiagent orchestration.
Dreaming lets agents analyze past sessions to find patterns — what worked, what didn't, what to try differently. Outcomes let agents self-correct against predefined success criteria during a session. Multiagent orchestration lets a primary agent delegate subtasks to specialized subagents, then synthesize results.
Harvey is using orchestration for legal workflows where a research agent finds precedents, an analysis agent evaluates relevance, and a drafting agent produces the brief. Netflix uses it for content operations. Wisedocs runs it for medical document processing.
The pattern is the same everywhere: break complex work into specialized pieces, let agents handle each piece, combine the results. This is a real architecture shift — agents are no longer single-threaded assistants, they're systems with components.
Where Multiagent Systems Break
Single-agent failures are straightforward. The agent does the wrong thing, you see the wrong output, you fix it. The failure surface is one agent, one task, one result.
Multiagent failures cascade. Agent A asks Agent B for data. Agent B returns data that's technically correct but formatted for a different context. Agent A uses it without validation. The final output looks plausible but is wrong in ways that only surface when a real user hits a specific path.
Three specific failure modes show up in orchestrated systems:
Specification drift between agents. The orchestrator describes a subtask in natural language. The subagent interprets it slightly differently. Each agent thinks it did its job. The gap between what was asked and what was delivered compounds across every delegation step.
Silent data transformation errors. Agent A passes a date as "May 7, 2026." Agent B parses it as ISO 8601 and gets "2026-05-07T00:00:00Z" — midnight UTC, which is still May 6 in US timezones. The legal brief now references the wrong filing date. No agent threw an error.
Circular validation. Claude's outcomes feature lets agents self-correct against success criteria. If the orchestrating agent defines the criteria and the subagent evaluates against them, the system is grading its own homework. The agent can converge on output that satisfies its internal checks while diverging from what the real-world outcome should be.
None of these are hypothetical. They're the distributed systems problems that software engineering solved decades ago with integration testing, contract testing, and end-to-end verification. Agent architectures are rediscovering them.
Self-Improving Is Not Self-Verifying
Claude's dreaming feature works like this: after a session ends, the agent reviews what happened and updates its approach for next time. Over many sessions, the agent gets better at tasks it does repeatedly.
The gap: getting better at a task and verifying the task was done correctly are fundamentally different operations. A code-writing agent can dream its way into producing cleaner code, better-structured functions, and more idiomatic patterns — while still missing a checkout flow that breaks on currency conversion for non-USD users.
Improvement optimizes the process. Verification checks the outcome against reality. You need both, and they can't be the same system.
This is why ProgramBench results are instructive. Meta's benchmark gave AI agents compiled binaries — tools like jq, ripgrep, SQLite — and asked them to rebuild the source code from scratch, using only the binary and its documentation. The agents could run the binary to learn what it does, but got no source code, no hints, no internet access.
The best model (Claude Opus 4.7) fully resolved zero of 200 tasks. Not because it couldn't write code — on many tasks, the agent produced 80-90% correct behavior. But ProgramBench evaluated with 248,000 behavioral tests generated through agent-driven fuzzing. The tests caught every deviation between what the agent built and what the binary actually does.
The lesson: code generation is not the bottleneck. Behavioral verification is. The agents wrote plausible code. The tests found where plausible diverged from correct.
What This Means for Testing Infrastructure
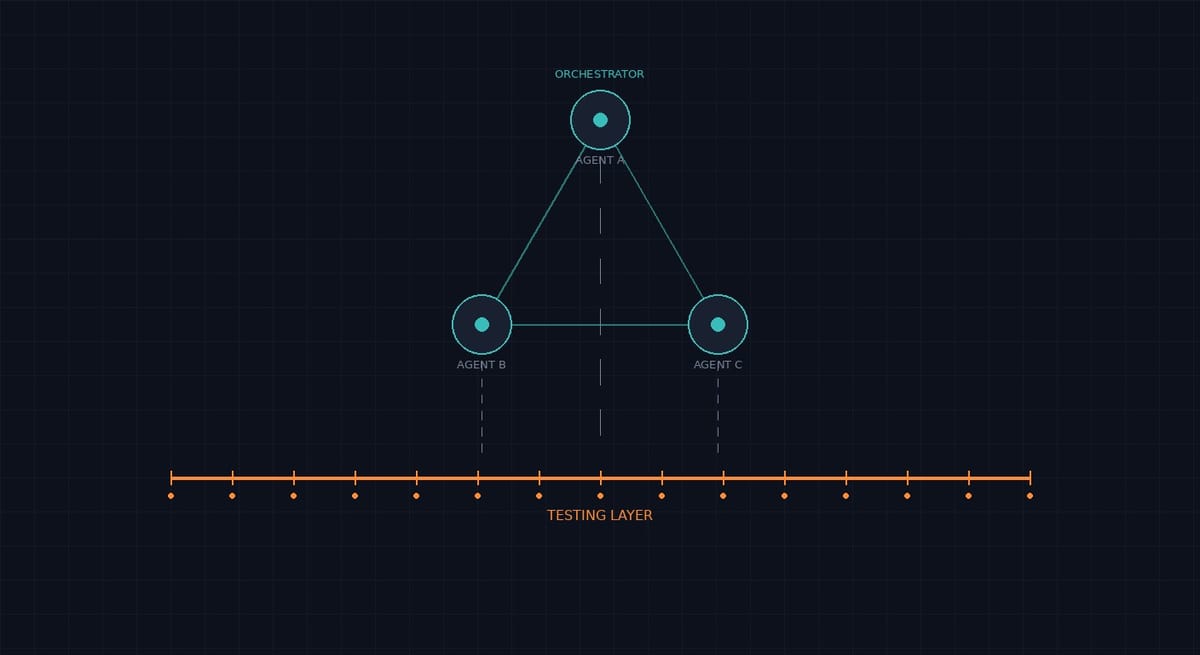
Every agent architecture diagram shows the same thing: an orchestrator at the top, specialized agents below, data flowing between them, results flowing up. What's missing from every diagram is the independent verification layer — something outside the agent system that continuously checks whether the end result actually works.
At HelpMeTest, this is the exact problem we built for. Tests that run against your production application, not inside your CI pipeline. Tests that check what your users experience, not what your code coverage report claims. When an agent deploys a change — or when three agents collaborating deploy a change — the question isn't whether each agent completed its subtask. The question is whether checkout still works, whether the login page loads, whether the API returns the right data.
This is the gap between agent-level metrics (did the subagent finish?) and system-level outcomes (does the product work?). Agent orchestration makes the first question easier to answer and the second question harder.
The Requirements Problem Gets Worse
We've written before about how AI coding agents skip requirements they weren't explicitly shown. A single agent working from a prompt will implement what it understood and nothing more. Cart persistence across page refreshes? If it wasn't in the prompt, it doesn't exist.
Multiagent orchestration amplifies this. The orchestrating agent decomposes a complex requirement into subtasks. Each decomposition step is a chance to lose a requirement. The orchestrator decides "implement checkout" means three subtasks: cart display, payment processing, confirmation page. Cart persistence wasn't a subtask, so no subagent builds it. Every agent completed every task. The feature is incomplete.
The fix is the same one we keep arriving at: define the requirements as runnable checks before any agent writes any code. If "cart persists across page refresh" is a test that runs continuously, no agent architecture can ship without it passing. The test doesn't care how many agents touched the code or which one was supposed to handle persistence. It checks the outcome.
What to Do About It
If you're building with multiagent systems — or planning to — three things are non-negotiable:
Define success outside the agent system. Your success criteria can't live inside the orchestrator's prompt. They need to be independently runnable checks against the real application. If the only thing verifying the output is another agent, you have a circular dependency.
Test the integration, not the components. Each subagent completing its task is a unit test. What you need is the integration test — does the combined output of all agents produce a working result? This means end-to-end testing against the deployed application, not assertions inside agent code.
Run tests continuously, not on deploy. Agent systems change behavior based on past sessions (dreaming), current context (outcomes), and task decomposition (orchestration). The same agent given the same task twice might produce different results. Continuous testing catches regressions that deploy-time checks miss because they only run once.
FAQ
Can't agents write their own tests?
They can, and they do — but an agent writing tests for its own output is the same as a developer reviewing their own pull request. You need an independent perspective. ProgramBench showed this clearly: agents produced code that looked right, but 248,000 externally-generated behavioral tests found the gaps.
Does this apply to simple single-agent setups?
Yes, but the urgency is lower. A single agent producing a single output is easier to verify manually. Once you have agents delegating to agents, manual verification doesn't scale. You need automated, continuous, independent testing.
What about Claude's outcomes feature — isn't that testing?
Outcomes let agents self-correct during a session. That's valuable for iterating toward a better result. But it's not the same as testing whether the deployed result works in production. Outcomes optimize the process; testing verifies the outcome. Different jobs.



